
{kind=link}
Table of Contents
Text To Speech
Text To Speech-As you browse the internet or navigate various computer interfaces, you may have noticed more and more references to ‘text to speech’ technology. Audio synthesis refers to a computer system’s ability to read written text aloud. The software converts the text into synthesized speech that sounds like a human voice. It powers many accessibility features and is increasingly used to provide more engaging user experiences.
Whether you want to listen to an ebook while multitasking, have messages or notifications read aloud while driving, or prefer listening to large volumes of text, audio synthesis can be an invaluable tool. However, the technology itself remains a mystery to many. This article will explore what exactly audio synthesis is, how it works, its applications, and recent advancements producing more natural and human-like speech synthesis. By the end, you’ll understand how audio synthesis powers many technologies you use daily.
Explaining Text-to-Speech Technology
Technology converts digital text into spoken words. It allows any digital text to be read aloud by a synthesized voice.
How Text-to-Speech Works
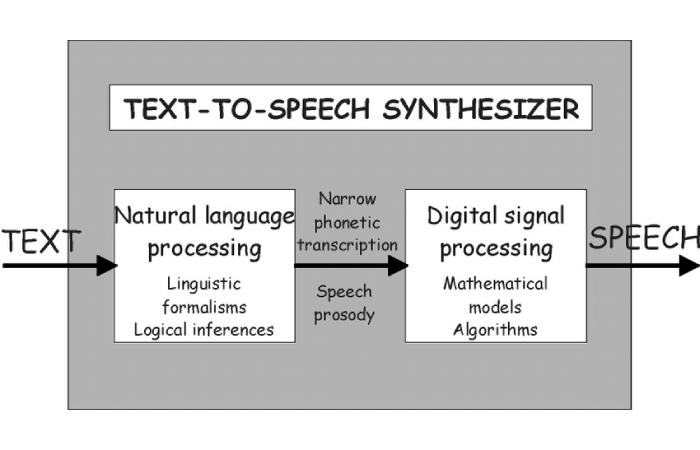
It software works by breaking down text into individual words and sounds. It then reassembles those into speech that resembles a human voice. The software contains a speech synthesizer, a text analyzer, speech phonemes, and a prosody generator.
The text analyzer breaks down the text into words, phrases, and punctuation. It then determines the proper pronunciation for each term based on an internal dictionary. The speech phonemes and prosody generator recreate natural speech’s flow, rhythm, stress, and intonation. They assemble the individual address sounds into words and smooth the transition between words to make the speech more natural.
Some systems use machine learning algorithms and neural networks to mimic natural speech more closely. The technology has advanced, producing human speech in many languages and accents. However, synthesized speech still does not sound authentic and genuine to most listeners.
audio synthesis is a technology for those unable to read text due to visual impairments or dyslexia. It is used in audiobooks, GPS navigation systems, voice assistants, and automated telephone menus. The potential applications of this versatile technology are extensive. With ongoing improvements, synthesized speech may be indistinguishable from human speech.
The Evolution of Text to Speech

TTS technology has come a long way since its origins in the 1950s and 60s. Early systems could only handle a few seconds of speech and sounded robotic.
Advancements in artificial intelligence, neural networks, and deep learning have enabled significant improvements in TTS over the past decade. Systems today can generate high-quality, natural-sounding speech for long-form content. They can even mimic different voices and speaking styles.
Modern TTS converts text into audio waveforms that are indistinguishable from human speech. It does this by analyzing massive datasets to build a complex model of language. The model learns how to convert sequences of words into the corresponding audio signals that comprise speech.
Leading TTS platforms offer features like multiple voice options, speech rate adjustment, and emotion or speaking style controls. Some services provide APIs and SDKs for integrating TTS into apps and services. A few even allow you to create custom voice models to generate speech in your chosen voice.
While imperfect, TTS has become an integral technology for various accessibility, productivity, and entertainment applications. Continued progress in neural networks and generative modeling will only enhance its capabilities. With TTS, we have a tool that gives a voice to the written word and expands the possibilities for sharing and consuming information.
Real-world Applications

Text-to-speech (TTS) technology has many practical applications in the real world.
Education
TTS can help make learning more accessible for students with visual impairments or dyslexia. Electronic texts can be converted to speech, allowing students to listen to their readings, lessons, and assignments.
Productivity
For busy professionals, TTS listens to documents, reports, and emails while multitasking. It allows you to absorb information while driving, exercising, or doing chores. Many email services, like Gmail, offer built-in TTS features.
Accessibility
TTS is important in making technology accessible to individuals with visual impairments. Screen readers that convert interface elements and audio synthesis provide computers and mobile devices access. Audiobooks and podcasts are other examples of TTS increasing accessibility to information and entertainment.
In summary, tts has become integral to many technologies we use daily. By converting text to natural-sounding speech, tts helps make information more accessible and makes us more productive. Advancements in neuronic networks and deep learning have made tts systems even more human-like, opening up more opportunities for tts applications in the future.
FAQ
audio synthesis technology converts text into synthesized speech. It allows for audible playback of written text. Some common questions about audio synthesis technology include:
How does text-to-speech work?
Text-to-speech systems use speech synthesis to generate audible speech from written text. The text is first analyzed to determine the correct pronunciation of words and the appropriate prosody or rhythm of speech. Speech sounds corresponding to each word are then selected and combined to generate speech. Additional processing is applied to make the speech sound more natural by adjusting the pitch, rate, and volume.
What Are The Benefits of Text-to-Speech?
It has several practical applications. audio synthesis can read text aloud for those unable to do so themselves due to visual impairments or dyslexia. It is also used to create audiobooks and podcasts from electronic text. Some mobile devices and GPS systems use audio synthesis to read incoming text messages aloud or provide turn-by-turn driving directions. It increases accessibility and allows people to multitask while absorbing information.
What Types Of Text Convert Into Speech?
Text-to-speech systems can convert most digital text into speech, including:
- Electronic books (ebooks) and documents
- Web pages
- Emails
- PDFs
- Text messages
The text must be in a format the reader can read to the speech engine. Scan images or handwritten text cannot be converted into speech. Proprietary or encrypted file formats may also be incompatible with some systems.
How Can I Use ?
Text-to-speech functionality is set into most major operating systems like Windows, MacOS, Android, and iOS. Third-party audio synthesis applications and plugins are also available for browsers, ebook readers, and other software. These tools allow you to highlight text and read it aloud at the click of a button. Some ebook readers also support hands-free reading using audio synthesis.
Conclusion
With the rapid improvements in artificial intelligence, text-to-speech technology has become remarkably advanced and helpful. You can now access highly accurate and natural-sounding voices that read your texts, emails, articles, and ebooks aloud. This technology allows you to listen to written information on the go when reading is not possible or convenient.
Whether you want to consume more content, improve literacy, or give your eyes a break, It provides an easy way to read written works aloud quickly and intelligently. The possibilities for how this technology can enhance productivity and accessibility are endless. Text-to-speech has fundamentally changed how we interact and share information in the digital age.